This document aims to do an analysis of the types of schema migrations we do in Mattermost and ways to make them non-blocking so as to improve the Mattermost upgrade experience. Historically, we have never put a lot of thought to the migration process. Developers would simply add a DDL statement and call it a day. But that causes a significant impact to large customers for whom downtime is not an option. This causes them to push back on upgrading their Mattermost version for a long time (sometimes for several years). This in turn, has some cascading effects like customers not able to get new features, performance improvements etc.
We want to improve the situation and make upgrades a worry-free experience for our customers. It definitely comes at a cost of writing more code and delaying some features to avoid breaking changes. This document will aim to uncover all those cases and provide best practices to follow so that we can hit the right balance.
We have two overarching goals and a third auxiliary goal.
We want to strictly follow this as much as possible (even at the cost of slower feature development).
Schema changes are always made synchronously when Mattermost starts up. This means the application won’t be ready to serve requests until all schema changes are applied. In most cases, the new application won’t be able to work until those schema changes are in place.
In a high availability environment, multiple instances will try to run migrations. To prevent this, a lock table is used in the migration system. Until migrations are completed, none of the instances will start. Once the lock is released by a node, another instance will obtain the lock, and check the migrations table. Since the previous node already applied the migrations, the remaining nodes won’t re-apply the migrations.
From Mattermost release v6.4, we have started using a schema-based migration system. We are now creating SQL statement files to run migrations. A developer must create migration files for each database driver. Since we want our migrations to be reversible, the developer must create one up script along with a down script. For instance, a single migration would have the following files:
000066_upgrade_posts_v6.0.down.sql000066_upgrade_posts_v6.0.up.sqlA file naming convention is used to determine the order in which the migrations should be applied that appends up|down.sql suffix to the migration name. We were using a database version before the new migration system which is why the versions exist in the migration file name in the example. Going forward, using version identifiers for future next migration files is not mandatory. A developer can add any information to the name if they think it’s going to be helpful.
We are using morph for the migration engine. The tool has a library and also a CLI. Mattermost server imports the library to have programmatic access to morph functions. A developer can use the morph CLI tool to test whether their migrations are working properly. Please follow instructions in the morph documentation to use the morph CLI tool.
A rough analysis of our past schema migrations shows the following (some very early migrations were skipped which would be considered as base Mattermost):
CREATE INDEX - 489
ALTER TABLE - 195
ADD COLUMN - 113
ALTER COLUMN - 51
DROP COLUMN - 25
ADD CONSTRAINT - 6
DROP INDEX - 124
CREATE TABLE - 60
UPDATE - 19
DELETE - 2
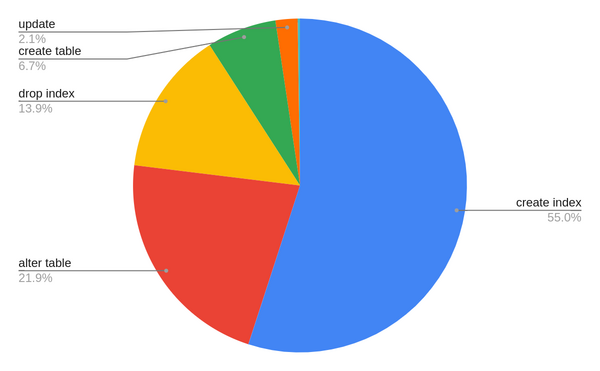
We will go through each of these migration types and discuss how we can make it non-blocking. This is a lengthy document, so for those wanting to directly look at the executive summary, we present it right now. And then expand on each section in detail later.
| Operation | Table rewrite | Concurrent DML allowed |
|---|---|---|
| CREATE INDEX | NO | YES |
| DROP INDEX | NO | YES |
| ADD COLUMN | NO | YES1 |
| ALTER COLUMN | YES | NO |
| DROP COLUMN | YES | YES1 |
| ADD FK CONSTRAINT | NO | YES (only selects)2 |
| ADD UNIQUE CONSTRAINT | NO | YES |
However, if you MUST do it, take a look into the following sections.
CREATE INDEX CONCURRENTLY does not take any locks.
Adding nullable columns happens in constant time from version 10. And from version 11 onwards, adding non-null columns with a default value also happens in constant time.
The catch here is to be able to handle denormalization optimizations which typically adds a new column but needs to backfill that with data before using the column. Take a look at the next section on how to achieve that.
This takes an exclusive lock. We strongly recommend you avoid doing this.
To give some context, we have this particular migration ALTER TABLE posts ALTER COLUMN props TYPE jsonb USING props::jsonb; which has caused us more pain than it was worth. Several large customers have faced problems with this migration where in some cases, it has been observed to take 8+ hrs. Therefore, we strongly suggest to avoid making any ALTER COLUMN changes until absolutely unavoidable (for example, security issues).
However, if you MUST do this, then see the example later.
Only a metadata lock is taken. No table rewrite takes place. The space is just marked as unused and later taken up by future DB writes.
Relatively rare, but out of those 6 cases, 2 are adding unique constraints. For example:
ALTER TABLE oauthaccessdata ADD CONSTRAINT oauthaccessdata_clientid_userid_key UNIQUE (clientid, userid);
This can be improved by first adding the index concurrently, and then attaching the index to the constraint. See example later.
Adding a foreign key in PostgreSQL takes a share row exclusive lock, which means only SELECT queries are allowed. It is possible to bypass the table scanning by adding a “NOT VALID” suffix, but then it defeats the purpose of having a foreign key. We recommend against doing it.
DROP INDEX CONCURRENTLY does not take any locks.
Does not lock any existing data so no issues.
An analysis shows that UPDATE statements roughly fall into one of these three categories:
UPDATE channelmembers SET MentionCountRoot = ..
UPDATE Channels SET TotalMsgCountRoot = ..
UPDATE ChannelMembers CM SET MsgCountRoot ..
In these cases, rather than operating on the entire table, we need to operate on batches at a time. See the example later on how to achieve that.
UPDATE Channels SET LastRootPostAt=0 WHERE LastRootPostAt IS NULL;
UPDATE OAuthApps SET MattermostAppID = '' WHERE MattermostAppID IS NULL;
This is possible to handle from the code itself using a COALESCE function. It makes the code more complicated, but it’s a cost we have to pay to reduce migration overhead.
UPDATE threads SET threaddeleteat = posts.deleteat FROM posts WHERE threads.threaddeleteat IS NULL AND posts.id = threads.postid;
UPDATE reactions SET channelid = COALESCE((select channelid from posts where posts.id = reactions.postid), '') WHERE channelid='';
UPDATE threads SET threadteamid = channels.teamid FROM channels WHERE threads.threadteamid IS NULL AND channels.id = threads.channelid;
UPDATE fileinfo SET channelid = posts.channelid FROM posts WHERE fileinfo.channelid IS NULL AND fileinfo.postid = posts.id;
We can take the same approach as in data migrations.
So far, there have been only a handful of DELETE statements in schema migrations. And mostly they have been for security issues. The general recommendation is to avoid running a full-blown DELETE statement that operates on the entire table, but rather operate on batches so as to avoid taking a lock on the entire table. This could either be done in a job since there is no new code waiting for this to be executed. (See above)
Follow this long-winded procedure:
For example, let’s say the next upcoming version is 8.4, and the next ESR is 8.6. So step 1 and 2, goes in 8.4. And in 8.7 onwards, we add the code to start using the new column, which will eventually be part of 8.12 (ESR after that). And then from 8.13 onwards, we can drop the column.
The following diagram should explain things better:
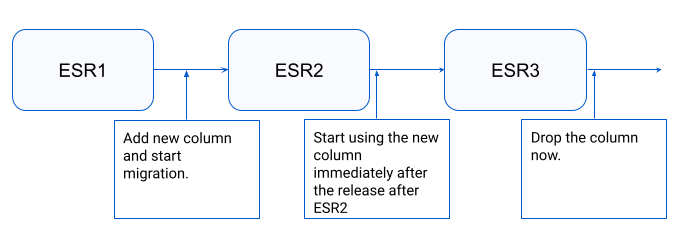
The reasoning behind this is some customers will only upgrade from ESR to ESR. So we need to ensure backwards compatibility with the previous version.
Following shows an example where we are adding a channel_count column to the status table. This is not exactly altering a column, but the idea remains the same, and you can extend this to fit your use-case.
ALTER TABLE status ADD COLUMN channel_count integer;
Our next objective is to migrate existing data. We do this in a 2-phase approach where we set up triggers to migrate all new data and in the background migrate old data in batches.
CREATE OR REPLACE FUNCTION public.update_status_channel_count()
RETURNS trigger
LANGUAGE plpgsql
AS $function$
DECLARE
member_count integer;
BEGIN
select count(*) into member_count from channelmembers where userid=NEW.userid;
NEW.channel_count := member_count;
RETURN NEW;
END
$function$
CREATE TRIGGER tr_update_status_channel_count
BEFORE INSERT OR UPDATE ON status
FOR EACH ROW EXECUTE PROCEDURE update_status_channel_count();
After this is taken care of, we need to create a job, which will migrate existing data in batches.
UPDATE status s SET channel_count=(SELECT count(*) FROM channelmembers cm WHERE cm.userid=s.userid) WHERE channel_count IS NOT NULL AND s.userid in (SELECT userid FROM status WHERE userid > '' ORDER BY userid ASC limit 10);
Then store the user id offset in the job metadata.
UPDATE status s SET channel_count=(SELECT count(*) FROM channelmembers cm WHERE cm.userid=s.userid) WHERE channel_count IS NOT NULL AND s.userid in (SELECT userid FROM status WHERE userid > <offset> ORDER BY userid ASC limit 10);
At this point, when the job finishes, the new column would be ready to use. And the triggers would take care of always keeping the data up to date.
DROP TRIGGER tr_update_status_channel_count on status
This deliberately skips renaming the column for simplicity. Depending on your use-case, you can do that if you want to. It is a fast operation that does not rebuild the table, so there are no issues.
CREATE UNIQUE INDEX CONCURRENTLY IF NOT EXISTS oauthaccessdata_clientid_userid_key on oauthaccessdata(clientid, userid);
ALTER TABLE oauthaccessdata ADD UNIQUE USING INDEX oauthaccessdata_clientid_userid_key; -- This is instantaneous
The idea would be to run the UPDATE statements in batches so as to avoid taking a large lock. This is similar to the second part in the column change example.
Following is an example where I update the channels table in batches setting a new column.
CREATE OR REPLACE FUNCTION public.update_in_batches()
RETURNS INTEGER
LANGUAGE plpgsql
AS $function$
DECLARE
id_offset text := '';
rows_updated integer;
BEGIN
LOOP
WITH table_holder AS (
SELECT id FROM channels
WHERE id > id_offset
ORDER BY id ASC limit 100
)
UPDATE channels c SET new='improved' WHERE c.id in (SELECT id FROM table_holder); -- change this query to whatever your requirement is
GET DIAGNOSTICS rows_updated = ROW_COUNT;
-- We have to run the select query again
-- becaue "select into" isn't allowed inside a CTE
-- and without CTE, we have to use a temp table (because you can't select into a table)
-- and with a temp table, you run into max_locks_inside_transaction limit.
-- Probably there is a better way but keeping things simple for now.
select id into id_offset from (select id from channels where id > id_offset ORDER BY id ASC limit 100) as temp order by id desc limit 1;
EXIT WHEN rows_updated = 0;
END LOOP;
return 1;
END
$function$;
{project_dir}/db/migrations/{driver_name}/.make migrations-extract to add your new migrations to the db/migrations/migrations.list file. This will ensure that there will be merge conflicts in case there is a conflict on migration sequence numbers with the master branch. Since we don’t want to have a collision on version numbers of the migration files, the developer should merge the upstream branch to the feature branch just before merging so that we can be sure that there are no versioning issues. In case of a version number collision, the build process will fail and main branch will be broken until it gets fixed.db_migrations table.db_migrations table whether the migration is applied or not.morph apply down --driver {your-driver} --dsn "{your-dsn}" --path {path-to-your-driver-specific-migration-files} --number 1db_migrations will stay consistent. You can edit the existing migration to be a no-op for future releases in this case.CREATE TABLE, ALTER TABLE etc.SELECT, UPDATE, INSERT etc.