One of the most important parts of the Mattermost source code is the one responsible for accessing the Mattermost database - the store. Every single database access is handled by the store, so we needed to find a way to extend its functionality while introducing as little complexity as possible. This is the reason behind the current layered approach using struct embedding.
Our store is responsible for storing and retrieving data, and sometimes we need to add functionality that is not strictly related to the database queries, for example, cache data or add instrumentation. Those are transversal tasks and don’t necessarily need to be in the same block of code.
Our approach is based in idea of a core store, the one accessing the source of truth (the database), and a set of layers on top of that adding extra behavior. All of them, the core store and all the layers must implement the same interface, in this case the store interface. This way, from the outside, there is no difference between our core store without layers, or our core store with 1000 layers on top of it.
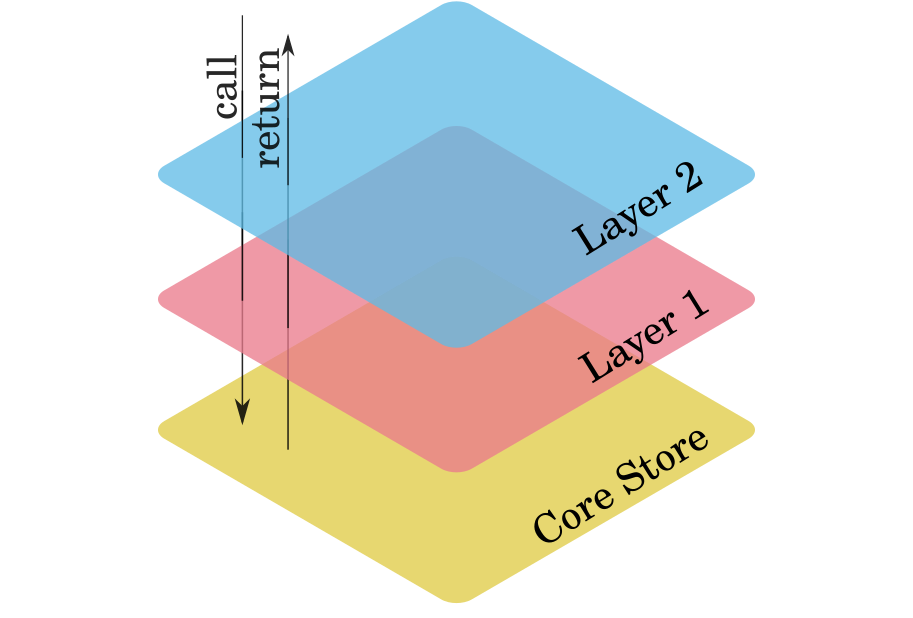
Each layer is going to embed another layer until the last layer embeds the core store. Each layer is going to override some methods (or all, depending on the layer). Each layer is responsible for deciding what is handled entirely by the layer (for example a cache hit) or is delegated to the underneath layer (for example a cache miss).
In our case, the core store is the SqlStore which encapsulates all the SQL queries execution. And the layers that we put on top of that are:
These four layers add functionality to our store without touching a single line of code of the SqlStore implementation.
How do we do that?
To solve this problem, we used structure embedding which is a tool provided by Go to extend the behavior of a struct based on another struct. I prefer to not use the term inheritance here because it is not correct; it is embedding, not inheritance. If you want to dive deeper into this concept, take a look at the video of the talk Embedding in go from Sean Kelly, he explains it better than I can.
As an example I’m going to create a small, simplified version of what we have, but storing the data in memory (with a small simulated delay) instead of a database (for simplification).
package main
import (
"fmt"
"time"
"github.com/pkg/errors"
)
type User struct {
Username string
FullName string
}
type Store interface {
GetUser(username string) (*User, error)
CountUsers() int
DeleteUser(username string) error
}
type MapStore struct {
db map[string]*User
}
func NewMapStore() *MapStore {
return &MapStore{db: make(map[string]*User)}
}
func (s *MapStore) GetUser(username string) (*User, error) {
time.Sleep(100 * time.Millisecond)
user, ok := s.db[username]
if !ok {
return nil, errors.New("User not found")
}
return user, nil
}
func (s *MapStore) CountUsers() int {
time.Sleep(150 * time.Millisecond)
return len(s.db)
}
func (s *MapStore) DeleteUser(username string) error {
time.Sleep(200 * time.Millisecond)
if _, ok := s.db[username]; !ok {
return errors.New("User not found")
}
delete(s.db, username)
return nil
}
...
This would be an example base store, now on top of that I’m going to create an example Cache Layer:
...
type CacheLayer struct {
Store
cache map[string]*User
}
func NewCacheLayer(substore Store) *CacheLayer {
return &CacheLayer{
Store: substore,
cache: make(map[string]*User),
}
}
func (s *CacheLayer) GetUser(username string) (*User, error) {
user, ok := s.cache[username]
if ok {
return user, nil
}
user, err := s.Store.GetUser(username)
if err != nil {
return nil, err
}
s.cache[username] = user
return user, nil
}
func (s *CacheLayer) DeleteUser(username string) error {
delete(s.cache, username)
return s.Store.DeleteUser(username)
}
...
Here we are creating a new struct called CacheLayer, this struct embeds the
MapStore (but it could embed any structs that implement the Store interface),
now we have a new struct that also implements the Store interface, but has a
different behavior. It will override two methods, GetUser and DeleteUser, and
CountUsers is going to be handled directly by the embedded store. The GetUser
will try to get the data from the cache, and if it’s unable to, it will get the data from the
underlaying store and store that in the cache. And for DeleteUser we remove
the entry from the cache if it exists.
My MapStore doesn’t know anything about the CacheLayer, and the CacheLayer only
knows that it have an underlying Store, but doesn’t know anything about it except
the interface.
Now that we have these layers that intercept things passing through the store we can do things like instrumentation, for example building a layer that counts the number of calls per method:
...
type CounterLayer struct {
Store
counterGetUser int
counterDeleteUser int
counterCountUsers int
}
func NewCounterLayer(substore Store) *CounterLayer {
return &CounterLayer{
Store: substore,
}
}
func (s *CounterLayer) GetUser(username string) (*User, error) {
s.counterGetUser++
fmt.Printf("GetUser calls: %d.\n", s.counterGetUser)
return s.Store.GetUser(username)
}
func (s *CounterLayer) DeleteUser(username string) error {
s.counterDeleteUser++
fmt.Printf("DeleteUser calls: %d.\n", s.counterDeleteUser)
return s.Store.DeleteUser(username)
}
func (s *CounterLayer) CountUsers() int {
s.counterCountUsers++
fmt.Printf("CountUsers calls: %d.\n", s.counterCountUsers)
return s.Store.CountUsers()
}
...
This layers intercepts all the calls made to the store and prints the number of calls so far.
Another more interesting layer would be a TimerLayer.
...
type TimerLayer struct {
Store
}
func NewTimerLayer(substore Store) *TimerLayer {
return &TimerLayer{
Store: substore,
}
}
func (s *TimerLayer) GetUser(username string) (*User, error) {
start := time.Now()
user, err := s.Store.GetUser(username)
elapsed := float64(time.Since(start)) / float64(time.Second)
fmt.Printf("GetUser time %f secons.\n", elapsed)
return user, err
}
func (s *TimerLayer) DeleteUser(username string) error {
start := time.Now()
err := s.Store.DeleteUser(username)
elapsed := float64(time.Since(start)) / float64(time.Second)
fmt.Printf("DeleteUser time %f secons.\n", elapsed)
return err
}
func (s *TimerLayer) CountUsers() int {
start := time.Now()
count := s.Store.CountUsers()
elapsed := float64(time.Since(start)) / float64(time.Second)
fmt.Printf("CountUsers time %f secons.\n", elapsed)
return count
}
...
This allows us to know how much time is invested in each call. Our TimerLayer
implementation is pretty similar to this one, but sends this data to
Prometheous instead of printing it.
This code is super repetitive, and in Mattermost we have a lot of method in our
store, so we didn’t write it by hand; we used generators to build the
TimerLayer and the OpenTracingLayer.
Using this kind of generator you can build all kinds of transparent layers that add extra behavior
like a KafkaLayer to send everything that happens to a kafka, a LoggerLayer
to log everything, a RandomDelayLayer to test weird behaviors on inconsistent
response times, or any other “middleware” that you can think about.
After everything is implemented we can glue it together by embedding the MapStore
inside the layers, initializing with some data, and testing how it works:
...
func main() {
mapStore := NewMapStore()
mapStore.db["test1"] = &User{Username: "test1", FullName: "Test User 1"}
mapStore.db["test2"] = &User{Username: "test2", FullName: "Test User 2"}
AppStore :=
NewTimerLayer(
NewCounterLayer(
NewCacheLayer(
mapStore,
),
),
)
// Getting the user 1 from the map store (showing the time)
AppStore.GetUser("test1")
// Getting the user 2 from the map store (showing the time)
AppStore.GetUser("test2")
// Getting the user 1 from the cache store (showing the time)
AppStore.GetUser("test1")
// Delete user 1 from the map store (showing the time)
AppStore.DeleteUser("test1")
// Counting users
AppStore.CountUsers()
}
If you execute the whole program you’ll get a similar output to this:
GetUser calls: 1.
GetUser time 0.100314 secons.
GetUser calls: 2.
GetUser time 0.100189 secons.
GetUser calls: 3.
GetUser time 0.000041 secons.
DeleteUser calls: 1.
DeleteUser time 0.200158 secons.
CountUsers calls: 1.
CountUsers time 0.150186 secons.
You can see the first two calls to GetUser are from the MapStore (because we have
the time.Sleep there), the third one is faster because you are using the
CacheLayer, and we can see all this thanks to the instrumentation layers that
we built.
This approach is not perfect, and does have some flaws. The main one is that the struct embedding doesn’t behave as one coming from object oriented languages would expect from inheritance - because is not inheritance. When you call a method in a struct that embeds another struct, and the method doesn’t exist in the parent struct, the embedded struct method is called, and at that point, you are in the embedded struct without any knowledge of the parent struct. So, if you call any other method of the struct, it will not be overridden and this can be error prone sometimes.
Another problem with this approach is related to how the layers work. You are wrapping entire methods, so it’s all or nothing. You can’t override part of the method, or reuse only certain parts of the underlying code easily and that can generate a ton of duplicated code depending on what you want to do.
We implemented this architecture change some months ago, and so far for us it’s been a very good way to add our instrumentation and cache without mixing responsibilities in our source code. And we believe that going forward we can add special layers to generate performance improvements relaying in other services, like key value stores, or graph databases and we’re looking into that.