In the daily life of a Site Reliability Engineer the main goal is to reduce all the work we call toil. But what is toil? Toil is the kind of work tied to running a production service that tends to be manual, repetitive, automatable, tactical, devoid of enduring value, and that scales linearly as a service grows. This blog post describes our journey to automate our nodes rotation process when we have a new AMI release, and the open source tools we built on this.
Apart from toil elimination we had specific problems that we needed to solve by building our tooling around:
To solve the above-mentioned problems we combined existing tooling that we had in place such as our cloud provisioner and our GitLab Pipelines with the new tools we implemented. Below are the steps we took to achieve this.
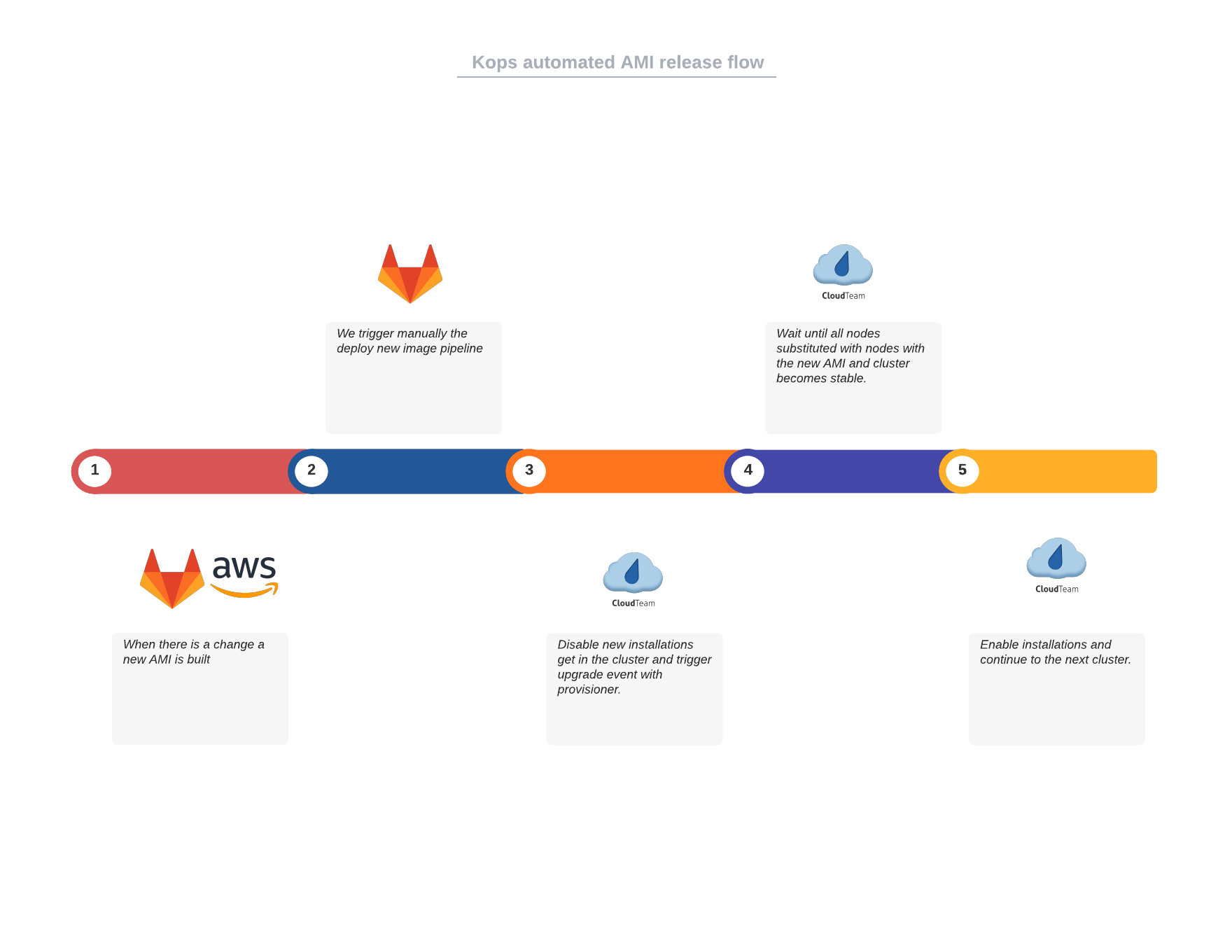
The flow of node rotation for our kops clusters
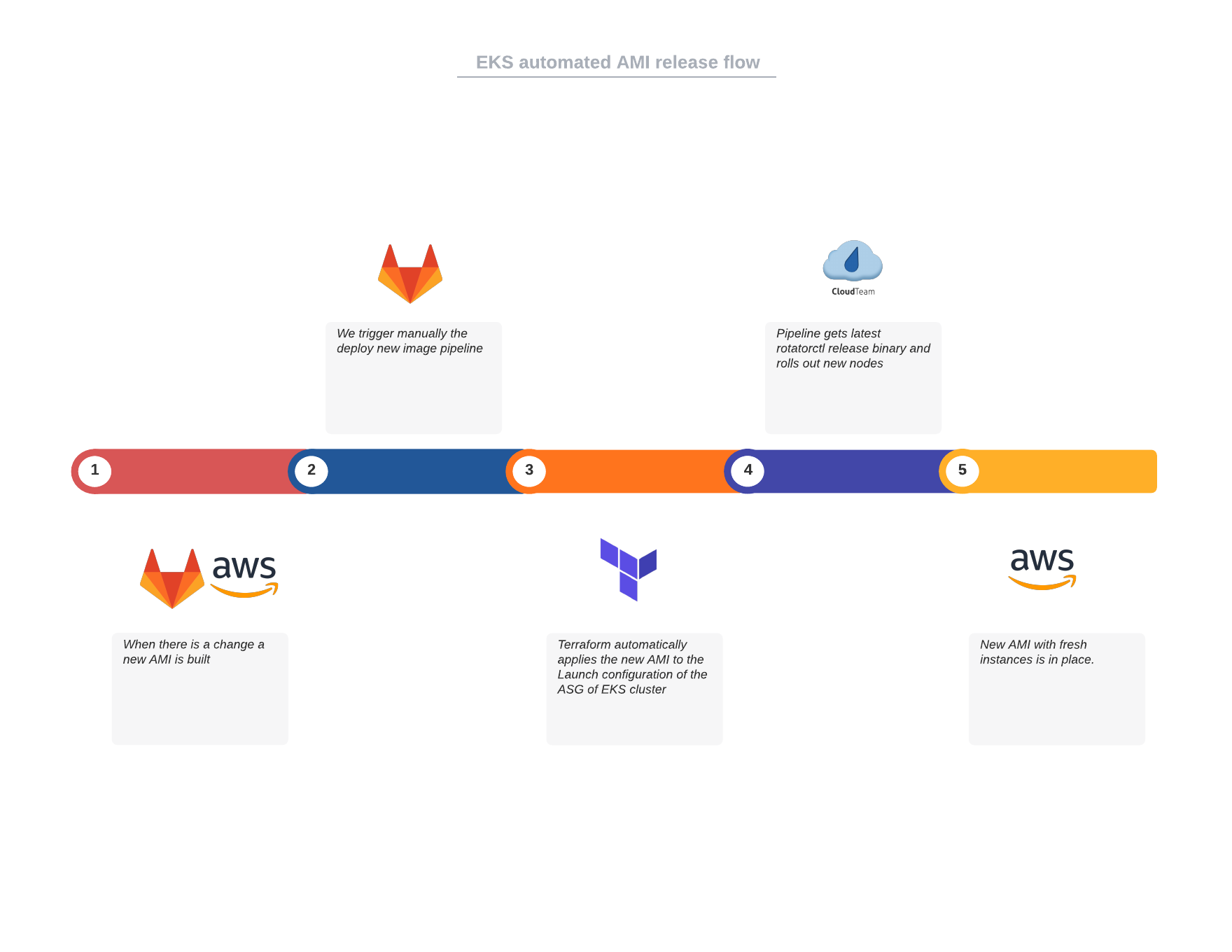
The flow of node rotation for our AWS EKS clusters
As we stated initially, all this work helped our team to get rid of a significant amount of toil work. By automating and improving these processes saved a lot of valuable time for the SRE team, before putting them in place there were cases that 2 or 3 people needed to participate and closely monitor these tasks.
Especially in the case of kops clusters, which rotate their nodes, this is a time-consuming task (2 to 8 hours depending on the cluster size and the environment) so investing on tooling over toil was a great choice.
This choice gave to our team the ability to roll out more regular AMI changes, which has resulted in a more secure and better performing underlying infrastructure. This way we can focus on what really matters, which is to serve a reliable and more secure cloud offering for our customers. These tools are not only useful for our team but for the wider community, as they solve a problem that many Operations and SRE teams are facing. Offering back tooling to the Open Source community for managing their infrastructure and their workloads is a core principle in our team.